
TCAPSATとは
テキストコピー支援プラグイン for SAT(TCAPSAT)は、SAT大正新脩大藏經テキストデータベースからコピー&ペーストする際、本文と無関係な文字列を削除し、テキストを整形するPCブラウザ用プラグインです。これにより経典の可読性を高め、文章執筆時の経典引用の負担を軽減させます。
::::機能一覧:::: | :::機能説明::: |
|---|---|
| 文章整形 (基本機能) | 本文と無関係な文字列を削除し、また偈頌などを整形します。 |
| 旧字変換機能 (異体字同定) | 旧字(異体字)を新字に変換し、経典の可読性を向上させます。 |
| 自動注釈機能 | カタログコードを参照し、経典名やページ番号などを自動で挿入します。 (カタログコードが取得できない場合、カタログコードを推測します) |
| ユーザ辞書 | 特定の文字を別の文字に置換させることが可能です。 |
::::::::分析機能:::::::: | :::機能説明::: |
|---|---|
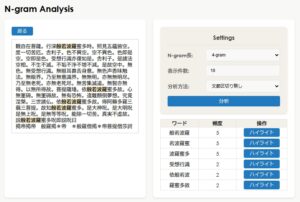
| n-Gram分析 (単一経典方式) | 経典の中で最も使用されている文字列を分析します。 (v1.3.0~)2つの経典を比較できるようにしました。 異本間の「単語」を使用するのに便利です。翻訳時代が異なる場合に有効です。 |
| n-Gram分析 (経典複合方式) | (v1.3.0~)経典の異本間の差分を抽出します。 曇無讖譯『大般涅槃經』、慧嚴譯『大般涅槃經』のように翻訳時代区分が近い場合に有効です。 |
| 形態素解析 | 仏教辞書を参照し、経典の原文を単語や品詞ごとに分類し、可読性を向上させます。 異体字同定と併用すると効果的です。 |
イメージ画像 - Image
インストール方法
Chromeウェブストアにアクセスして、インストールを選択してください。
PC版 Chrome 及び Microsoft Edgeに対応しています(Chromium系ブラウザで動作します)。
機能を一時的に停止する方法
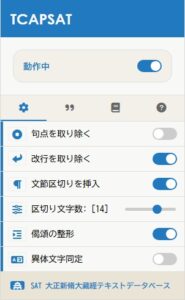
◆ 設定方法
パズルアイコン(![]()
動作中/停止中」のトグルを切り替えることで、一時的に停止させることができます。
オプション機能について
ユーザの好みにあわせて、様々なコピー方法を選択することができます。
拡張機能を使用するにはパズルアイコン(![]()
◆ 句点を取り除く
"句点を取り除く" 機能を使うことで、文中の「。」を取り除くことができます。
◆ 改行を取り除く
"改行を取り除く" 機能を使うことで、文中の改行を取り除くことができます。
これにより行を跨いだ文章をコピーする際、文章の行の区切りを取り除きます。
注意:
全ての改行が取り除かれる点にご注意ください。"文節区切り" 機能と併用することをおすすめします。
◆ 文節区切り
"文節区切り" 機能では、特定の条件下で文節の区切りに改行を加えます。
"改行を取り除く" 機能と併用することで不要な改行を削除しつつ、文節に改行を加えることができます。
使用上の注意:
大正新脩大藏經は、通常1行あたり16~17文字で構成されています。
そこで、この機能では「1行が規定の文字数以下(画像、句点を除く)の場合」を文節とみなし、改行を加えます。
(最初の1行目にかぎり、文章を途中からコピーする場合には、改行を加えません)
また、行の最初の1文字目あるいは最後の1文字が全角スペースの場合、特別行扱いとし、改行を加えます。
但し、いくつかの例外があります。例えば、次のようなケースです。
(1) 句点の数によって、1行が16文字未満になる場合。
(2)Unicodeに存在しない文字のため、文字を画像形式で表示している場合。
そこで文字数は12~15文字で任意に設定可能です。
◆ 偈頌の整形
"偈頌の整形" 機能では、偈頌部分の空白を取り除き、一文字繰り下げてコピーすることができます。
"改行を取り除く"と併用した場合にも、偈頌部分の改行はそのまま残します。
例:
| テキスト整形前 | テキスト整形後 |
|---|---|
時梵童子以偈報曰〇〇〇〇典尊汝所修〇爲欲何志求〇〇〇〇〇〇〇〇今設此供養〇當爲汝受之又告大典尊。汝若有所問自恣問之。當爲 | 時梵童子以偈報曰〇典尊汝所修〇爲欲何志求〇今設此供養〇當爲汝受之又告大典尊。汝若有所問自恣問之。當爲 |
使用上の注意:
一部の偈頌には非対応です。行の初めに連続した4文字の全角スペースがない場合、「偈頌」として認識されません。
◆ 異体文字同定
"異体文字同定" 機能では、多くの旧字体(異体字)を「新字体」に変換することができます。
なお、異体文字同定にはCC BY 4.0資料である『史料編纂所データベース異体字同定一覧』(東京大学史料編纂所所蔵)を独自に.json形式へと変換しています。
データの整合性をあわせるため、本ツールを使う場合には異体文字同定のデータは上記のものを活用することをお勧めいたします。
例:
| テキスト整形前 | テキスト整形後 |
|---|---|
| 歸依三寶。悉隨順行。略説如前。地大大神。斷除疑惑。 | 帰依三宝。悉随順行。略説如前。地大大神。断除疑惑。 |
◆ 自動注釈機能
SATからコピーする際、カタログコード(Tからはじまる番号)を参照して経典名や大正蔵のページ数を自動で入力します。
注釈を挿入する場所は、文章末、文章末(改行あり)、LaTeX方式から選択することが可能です。
条件 | 仕様 |
|---|---|
| 最初の行と最終行のカタログコードが取得できる場合 | カタログコードから正確に取得します。 経典名の取得は最初の行を参照します。 |
| v1.2.7より 最終行のカタログコードのみ取得している場合 (最初の行の文章途中からコピーした場合) | 2行目を参照することにより1行目のカタログコードを推定します。 (使用の際には、引用箇所があっているかを必ずご確認ください) |
SAT 2018版での使用方法
SAT 2018版の標準設定ではカタログコードが付与されていません。
SAT 2018で使用する場合には、SAT 2018の設定上にある「CITE」ボタンから上記の形式を選択し、「行」ボタンをクリックして表示させてください。
分析機能
◆ N-gram分析
2-gramから6-gramまでを用いて、経典内でよく使われる単語を調べることができます。異訳などとの比較に便利です。
◆ 形態素解析
仏教辞書及び漢語辞書などに基づき形態素解析を行うことで、経典の可読性を向上させます。
なお、V1.2.6以降では、ユーザがJSON形式で辞書化したものを登録することができます。
使用上の注意:
現在、形態素解析では次のような問題を抱えています。
「会中有比丘比丘尼…」といった白文の正しい分類は「会中 。 有 。 比丘 比丘尼」です。しかし、仏教辞書を優先した場合「会 。 中有 。 比丘 比丘尼」と誤分類することがあります。これは仏教用語である「中有」が優先されるためです。
そこで解決方法の一つとして辞書の優先度に係数を与え、単語出現率などと乗算して順位をつけるといった方法が検討されています。
このようなことから、将来のアップデートにおいては、それまでの分析方法から変更となる可能性がありますので、ご了承ください。
注意事項
使用辞書について
権利問題を回避し、先人の知識を最大限活用するため、原則としてパブリックドメインのもの(50年または70年(TPP11)経過し、新たに編集されていないバージョンのもの)またはクリエイティブ・コモンズ・ライセンスのもの、GPLライセンス・MITライセンスにより公開されているもの等を使用しています(それぞれのライセンス方針に適切に従う)。
『望月仏教大辞典』及び『大漢和辞典』については、花園大学国際禅学研究所のデータを底本として『漢字データベースプロジェクト』によって加工されたテキストデータを(MITライセンス)、独自で加工したうえでjson形式に変換した。本データの使用には、MITライセンスに基づく条件が適用されます。
使用辞書を増やすことによって、分析品質の向上が期待できます。ライセンス問題をクリアできる資料をお持ちの方はご一報ください。
(パブリックドメインの辞書についても、編集などが加わり、新たにライセンスが発生しているものについては対応できません)。
また研究機関以外で『WEB版新纂浄土宗大辞典』などの見出し語リスト等を公開している非営利法人のサイト等ありますが、CCの資料ではないことから、権利が確認できない限りは採用できません。
見出し語リストに関する権利問題の当団体の考えとしては、一定の規則に基づいて編集されたものについては権利が発生しうるとして慎重に取り扱うこととします。
今後、考えられうる資料
・禿氏祐祥監修『仏教辞典』(パブリックドメインのため)
・『織田仏教大辞典』(TPP11成立前にパブリックドメインとなっているため)
有用である可能性が高く検討している資料
・『大智度論』のテキストデータ
免責事項
本プラグインはテキスト整形を補助するツールではあり、多くのパターンで活躍しますが、必ずしもすべてのパターンに一致するわけではありません。
本プラグインを使用して不具合が発生した場合、また適切に文字列を処理できなかった場合でも、当サイトは責任を負いません。利用の際には、ご自身で必ず原文及び引用箇所をご確認ください。
リンクについて
当サイトはリンクフリーです。
ただし、当サイトのコンテンツを複写・複製することは固く禁止致します。
トップページ: https://sosesha.com/
プラグイン配布ページ: https://sosesha.com/sat_plugin