
◆ N-Gram分析を使う
◆ 概要
N-Gramとは、「如是我聞一時仏在」といった文章において、「如是」「是我」「我聞」…と分割していく方式です。N値が3の場合には、「如是我」「是我聞」「我聞一」…と分類していきます。このようなN-Gramを用いて経典を分析することにより、翻訳テキストにおける経典差分が明らかにすることができます。
◆ N-Gram(経典複合方式)の分析方法(v1.3.0-)
経典複合方式は、2つの経典を合算して、頻度を分析するという方法です(仕様としては、両経典に同じ単語が1つずつある場合に抽出できます)。大正蔵No.374 曇無讖訳『大般涅槃経』と、大正蔵No.375 慧嚴訳『大般涅槃経』を比較してみましょう。ここではN-Gram長を12と設定しました。N-Gram長を「12」から順にハイライトしていき、「2」までハイライトすると次のような結果がでます。

このように同時代の翻訳テキストでは一定の共通性があることがわかります。
上述の例では、「拘尸那國」が「拘尸城」、「阿利羅跋提河」が「阿夷羅跋提河」といった単語の違いから、「青黄赤白頗梨馬瑙。光遍照」と「青黄赤白頗梨馬瑙光。遍照」といった大正蔵特有の句点の打ち方の違いまでが明らかになります。
◆ N-Gram(単一経典方式)の分析方法
一方、N-Gramの単一経典方式では、単一の経典から同じ単語の頻出度数を計測します。これにより、訳出年代の違いがあっても比較が可能です。例えば、仏教の用語において「愛」の原語は、サンスクリット語で「anunaya」「anurodha」「sakta」「tṛṣṇā」「vyavasita」「rucitā」「kāma」「sneha」といった可能性があります。この「愛」は「親愛」「法愛」「信愛」「渇愛」などと適切に翻訳され、また『大般涅槃経』でいうところであれば「餓鬼愛」や「法愛」と分類され、有部の論書や『大智度論』では「汚れた愛」、「汚れていない愛」と適切に分類されています。このように多くの場合、適切に翻訳されているものの、だからといって必ずしも適当な訳語となっているとは限りません。このような場合に、複数の漢訳テキストの定量的な比較によって、「愛」と訳出された原語の違いを予測することができると考えられます。
◆ 形態素解析を使う
1. 原文を貼り付ける
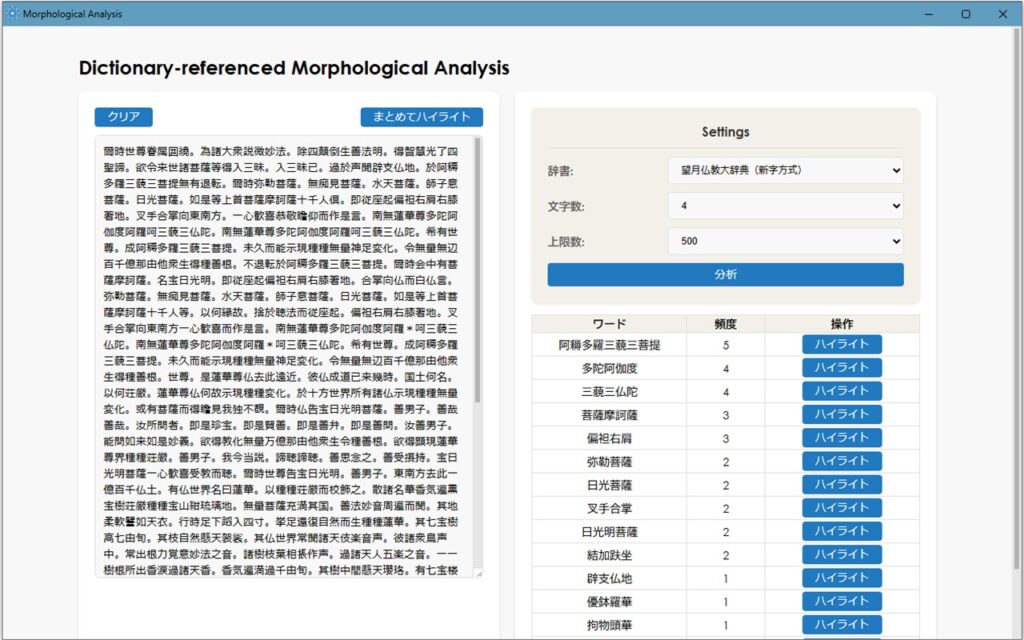
まず最初に、メインで使用する辞書を選択します(ここでは『望月仏教大辞典』を選択しています)。
この際、文字数を「3~6」に設定します。これは辞書と整合性の高い文字列を参照させるためです。
ここで「まとめてハイライト」をクリックします(特定の文字列のみハイライトしたい場合は、「操作」から行ってください)。
例:
「般若波羅蜜多」という文章を辞書で参照した時に、「般若」「波羅蜜」「般若波羅蜜多」といったキーワードが抽出されます。したがって「般若波羅蜜多」という単語で区切るには、文字数の多いものから優先でハイライトしていく必要があります。
(システム処理自体は文字数の多いものから優先されるようになっています)
また、辞書には複数の異体文字が登録されていないため、原文の貼り付けは異体文字同定機能をオンにすることで、単語の補足率があがります。
2.文字数を減らして、用語をハイライトさせる
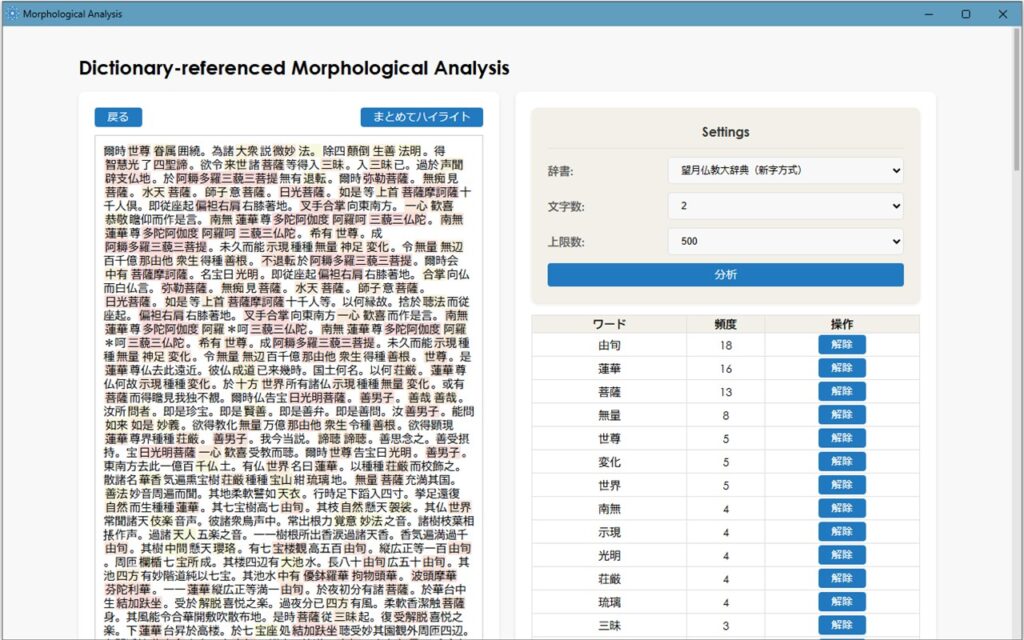
次に文字数を「2~3」程に下げ分析をクリックすると、次の仏教用語一覧が抽出されます。
ここで再び「まとめてハイライト」をクリックして、原文と紐づけをさせます。
3.品詞をハイライトさせる
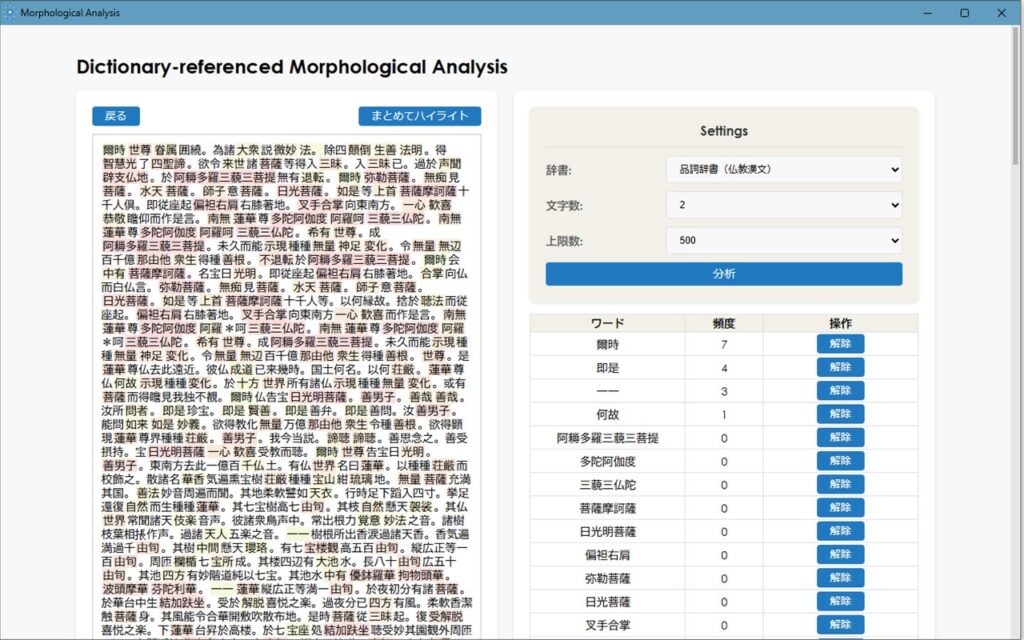
次に辞書を「品詞辞書」に変更します。
文字数を「2」程に下げて分析をクリックすると、品詞単語一覧が抽出されます。
ここで再び「まとめてハイライト」をクリックして、品詞をハイライトさせます。
4.文字数の少ない用語・品詞をハイライトさせる
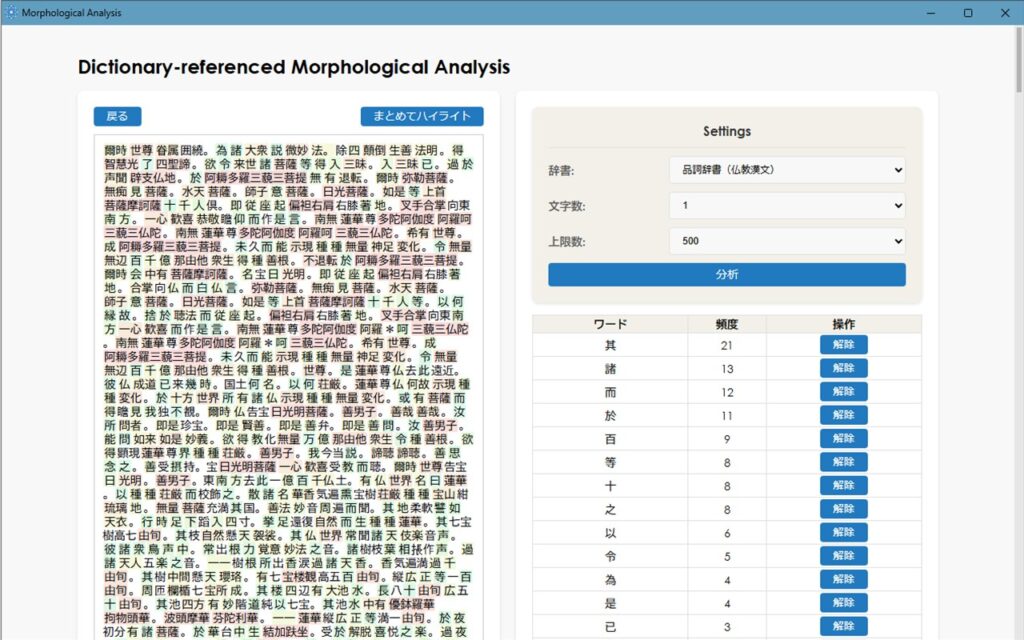
次に辞書をメインの辞書に戻し、文字数「1」で仏教用語をハイライトさせます。
さらに「品詞辞書」に戻し、文字数「1」で品詞をハイライトさせます。
品詞辞書は今後、更新していきます。
◆ 使用辞書について
権利問題を回避し、先人の知識を最大限活用するため、原則としてパブリックドメインのもの(50年または70年(TPP11)経過し、新たに編集されていないバージョンのもの)またはクリエイティブ・コモンズ・ライセンスのもの、GPLライセンス・MITライセンスにより公開されているもの等を使用しています(それぞれのライセンス方針に適切に従う)。
『望月仏教大辞典』及び『大漢和辞典』については、花園大学国際禅学研究所のデータを底本として『漢字データベースプロジェクト』によって加工されたテキストデータを(MITライセンス)、独自で加工したうえでjson形式に変換している。本データの使用には、MITライセンスに基づく条件が適用されます。